CLIP2GAN: Towards Bridging Text with the Latent Space of GANs
CLIP2GAN: Towards Bridging Text with the Latent Space of GANs
成果展示:

⭕摘要(译)
在这项工作中,我们致力于文本引导的图像生成,并通过利用CLIP模型和StyleGAN提出了一个新的框架,即CLIP2GAN。CLIP2GAN的核心思想是将CLIP的输出特征嵌入空间和StyleGAN的输入潜在空间进行桥接,通过引入映射网络实现。在训练阶段,我们使用CLIP对图像进行编码,并将输出特征映射为潜在代码,进一步用于重建图像。这样,通过自监督学习的方式对映射网络进行优化。在推理阶段,由于CLIP可以将图像和文本同时嵌入到一个共享的特征嵌入空间中,因此我们将训练架构中的CLIP图像编码器替换为CLIP文本编码器,同时保留下面的映射网络和StyleGAN模型。因此,我们可以灵活地输入文本描述来生成图像。此外,通过简单地将一个属性的映射文本特征添加到一个映射的CLIP图像特征中,我们可以有效地将该属性编辑到图像中。大量的实验证明了我们提出的CLIP2GAN与以前的方法相比具有优越的性能。
⭕梳理
➡️论文试图解决什么问题?
以往Gan相关的工作倾向于通过直接控制潜在的代码特性来实现图像应用,这使得显式的意图很难介入。文字能够精确地表达人的需求,可以考虑利用文字直接控制潜在空间,实现文字引导的图像生成和图像编辑任务。
本文中提出了一个新的框架CLIP2GAN,用于文本引导的图像生成和编辑。
➡️这是否是一个新的问题?
不是。文本引导的图像生成是图像生成中一个有趣的主题,其中基于gan的模型显示了更好的样本质量。例如TediGAN训练编码器将文本映射到StyleGAN的潜在空间。
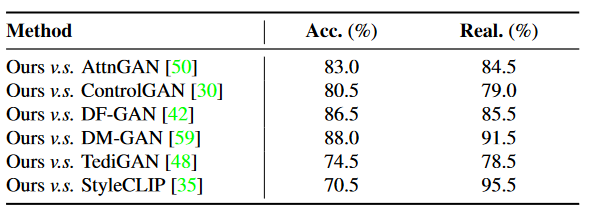
但是与以前的大多数工作相比,论文的方法在不使用文本训练的情况下取得了更好的性能(文本引导图像生成)。(参照文章对比工作 AttnGAN , ControlGAN , DF-GAN, DM-GAN, TediGAN, and StyleCLIP)

➡️这篇论文到底有什么贡献?
文章提出了一个新的框架,即CLIP2GAN,它使文本引导生成任务具有无文本训练,在给定相同的输入文本的情况下生成不同的高质量图像。将框架应用于图像操作,允许直接使用文本属性编辑真实图像。在公共数据集上的大量实验证明了该框架的有效性和优越性。该方法生成的图像具有较高的评价质量和较好的视觉效果。
⭕方法
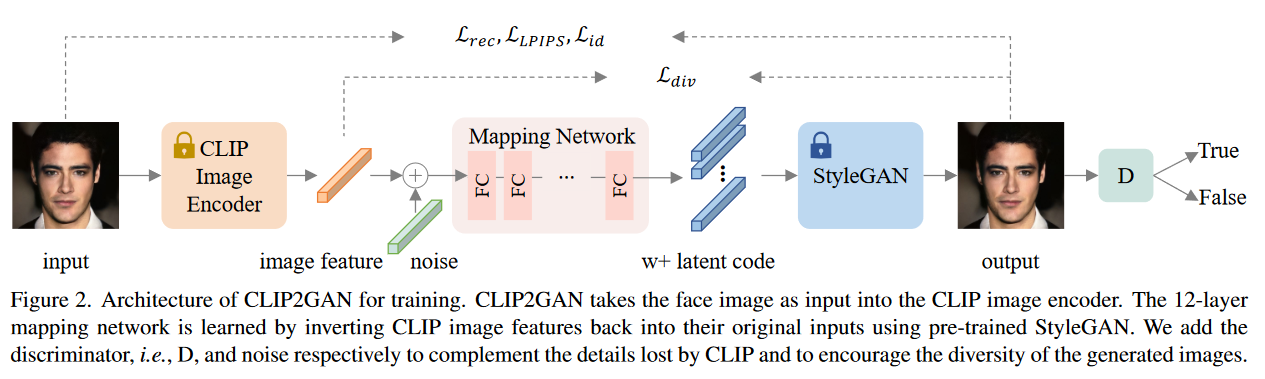
流程如图所示,使用预训练的CLIP模型,预训练的Stylegan2模型,在两个模型之间添加一个映射网络,使得该映射网络能够将CLIP的多模态嵌入空间映射到StyleGAN的w +隐空间中。输入图像经过CLIP Image Encoder的也是一个伪文本特征.
文章提出映射网络由12层全连接网络构成,每层后接一个leaky ReLU激活层。训练的主要目的也是优化映射网络 ,让它能更好的把CLIP多模态嵌入空间中的特征映射到StyleGAN的隐空间里。
图像重建过程中存在下述问题,针对问题提出了相应的解决方案。
- 直接添加映射网络,在反演CLIP及GAN生成图像时都会存在细节损失问题(尤其是头发,皮肤纹理,背景),分析是CLIP只是提取了图像信息的主要的512维特征信息而忽略了其他。于是使用类似Gan的训练模式,引入了一个判别器来判断所获得图像的真实性。将其与映射网络进行对抗训练,在不影响特征表示的情况下,对图像细节进行补充,提高生成质量。
- 重建生成图像缺乏多样性(个人理解这里指的应该是通过text encoder-mapping network-stylegan的生成图像),文章的优化方案是保留多样性损失,鼓励在引入不同的噪声向量时产生不同的结果。即输入任意特定的文本描述,能够生成多张与文本特征匹配但具有唯一性的图像,附加高斯噪声为μ = 1,σ2 = 0.36。
➡️文本引导图像生成
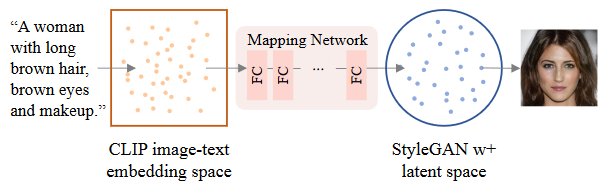
用上述训练好的映射网络桥接CLIP Text Encoder输出的特征作为输入,输出StyleGan隐空间特征,再进行图片生成,至此完成了文本引导的图像生成,并且过程中不需要对文本数据进行训练。
➡️损失函数设计
文章考虑了Reconstruction Loss,Perceptual loss,Adversarial loss,Identity loss,Diversity loss分别记为。
- Reconstruction Loss 计算源图像和生成图像的 l2 距离,假设数据符合高斯分布,这会导致生成相对原图像更平滑的图像。
- Perceptual loss 衡量原图像和重构图像的差异性, LPIPS的值越低表示两张图像越相似,反之,则差异越大,改善由重建损失引起的平滑问题。
- Adversarial loss 对于生成器和鉴别器应用WGAN-GP损失函数(WGAN-GP相对于WGAN引入了一个正则项,效果更好。WGAN衡量真实图像分布和生成图像分布之间的距离,基本解决了collapse mode的问题,确保了生成样本的多样性)计算。
🔗WGAN理解 - Identity loss 身份损失,防止生成前后是不同的人,使用effective arcface model 衡量生成前后人脸是否一致。
- Diversity loss 即在CLIP多模态嵌入空间的 添加μ = 1,σ2 = 0.36的高斯噪声得到 ,进而由得到 和 生成的图像… 计算的是 距离,也就是最小值绝对偏差。(目前的理解是,按照降低损失的思路,应该尽可能让分母更大给或者分子更小,比如在保持 不变的情况下,让 更小,也就是生成前后图像语义特征尽可能保持相同,而实际图像最好能够有一定的差异性,这样可以更好地保持生成多样性)
最终总的损失计算为以上损失的加权和。
➡️文本引导图像编辑
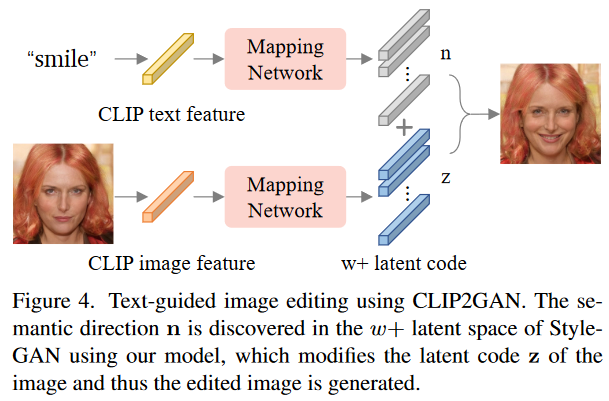
将描述文本输入到CLIP文本编码器中,得到CLIP文本特征。然后通过预训练的映射网络导出StyleGAN隐空间中的向量n,由于映射网络桥接了CLIP特征空间和StyleGAN隐空间,因此被认为是特定语义的法线方向。其中M代表映射网络,和为CLIP的文本和图像编码器,z表示StyleGan的隐空间潜码z。
StyleGan通过迭代使得隐空间潜码z向着特定语义法线方向变换得到新的分布,最终得到生成的图像。获得原图片的分布潜码后,将其沿特定语义法线方向n进行变换即可实现对图片的编辑。其中公式中β表示沿特定语义法线方向变换的程度。
⭕消融实验
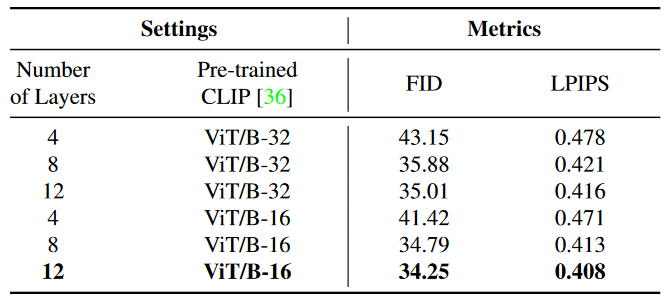
为了评估网络设计的有效性和必要性,文章修改了具有不同网络层数的映射网络和CLIP的预训练模型。可以观察到当网络层数较少时,该框架在多个指标上表现较差。然而,随着层数的增加,它对性能提升的意义不大,还大大增加了网络的复杂度。
CLIP的特征空间在图像和文本之间具有语义意义,因此使用更强的联合空间( ViT / B-16 )可以提高生成结果。
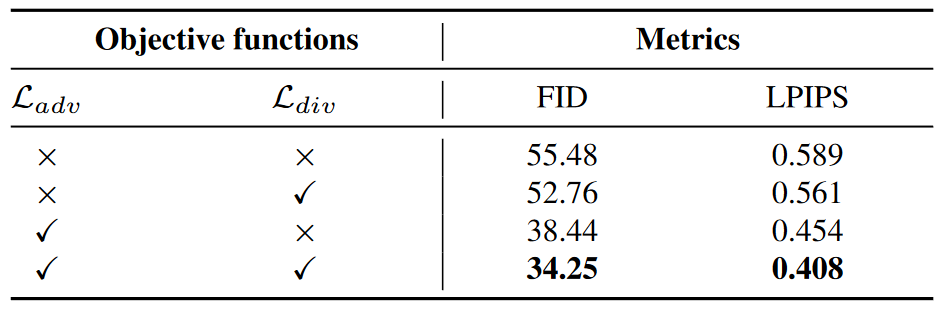
在CelebA - HQ 数据集上对目标函数进行消去(对抗损失和多样性损失), 如下表所示,证明了引入对抗损失和多样性损失确实可以获得更好的结果。去除对抗性损失会损失图像的真实感,而去除多样性损失会导致模式收敛(pattern convergence)。
⭕写在最后
感觉读一篇论文和自己去讲一篇论文还是有一定差距的。跟着自己做的PPT顺了一下自己要讲的思路。(其实是我讲的时候偷偷念的txt->_->)
文本与GANs潜空间的桥接
➡️论文背景: 利用文字直接控制潜在空间,实现文字引导的图像生成和图像编辑任务,这也是这篇论文主要做的工作。➡️论文方法: CLIP2GAN模型由预训练的视觉语言模型( CLIP )、映射网络和预训练的生成模型( StyleGAN )组成。输入图片经过CLIP图像编码变成图像特征,同时也是伪文本特征。映射网络在CLIP多模态嵌入空间和StyleGAN隐空间之间建立映射关系, 将一个512维的文本特征f_𝑡𝑒𝑥𝑡或图像特征f_𝑖𝑚𝑔从CLIP的多模态嵌入空间转换到StyleGAN的w +空间,从而得到一个18 × 512维的隐码z。最后再由stylegan生成图像。
➡️问题及优化: 论文提出在训练过程中存在两点问题。一个是直接添加映射网络,在反演CLIP及GAN生成图像时都会存在细节损失问题(尤其是头发,皮肤纹理,背景), 推测这是因为CLIP仅仅提取了图像主要的512维特征而忽略了其他的细节。另一个问题是生成的图像示例缺乏多样性。因为训练是要重建相同的图像,像素之间的损失主要集中在重建的相同图像,而不是不同的图像,但是如果要根据文本去生成符合描述的图像是需要具有多样性的。
对于第一个问题,论文的解决方案是引入一个判别器来判断所获得图像的真实性。将其与映射网络进行对抗训练,在不影响特征表示的情况下,对图像细节进行补充,提高生成质量。
对于缺乏多样性的问题,论文在获得的图像特征后引入噪声向量。这样在文本引导图像生成的工作中,输入任意特定的文本描述,能够生成多张与文本特征匹配但具有唯一性的图像,(额外的高斯噪声为μ = 1,σ2 = 0.36。)然后论文的方法可以在两个应用场合得到比较好的效果。一个是文本引导图像生成,一个是文本引导图像编辑。
➡️文本引导图像生成: 在文本引导图像生成中,可以用上面训练好的映射网络链接CLIP多模态嵌入和StyleGAN隐空间,输入文本描述,经过CLIP的文本编码器得到多模态嵌入空间的文本特征,文本特征通过映射网络被投影到stylegan的隐空间,然后通过StyleGAN生成与文本描述相符的图像。这一过程中都是不需要对文本数据进行训练的。➡️文本引导图像编辑: 对于文本引导图像编辑的话,需要输入一个源图像,然后输入想要编辑的文本特征,然后让源图像和这个文本特征分别通过CLIP的图像编码器和文本编码器得到源图像的特征和描述文本的特征。依旧通过映射网络把这两个特征向量投影到stylegan的隐空间。然后通过stylegan输出编辑后的图像。
对于如何在stylegan的隐空间里把文本特征和图像特征糅合在一起,论文提出了一个理解是映射网络桥接了CLIP特征空间和StyleGAN隐空间,经过映射网络后的stylegan隐空间中文本特征被认为是特定语义变换的法线方向n。因为stylegan通过迭代使得隐空间潜码z向着特定语义法线方向变换得到新的分布,最终得到生成的图像。获得原图片的图像特征分布潜码后,将其沿特定语义法线方向n进行变换即可实现对图片的编辑。其中公式中β表示沿特定语义法线方向变换的程度。➡️论文实验:
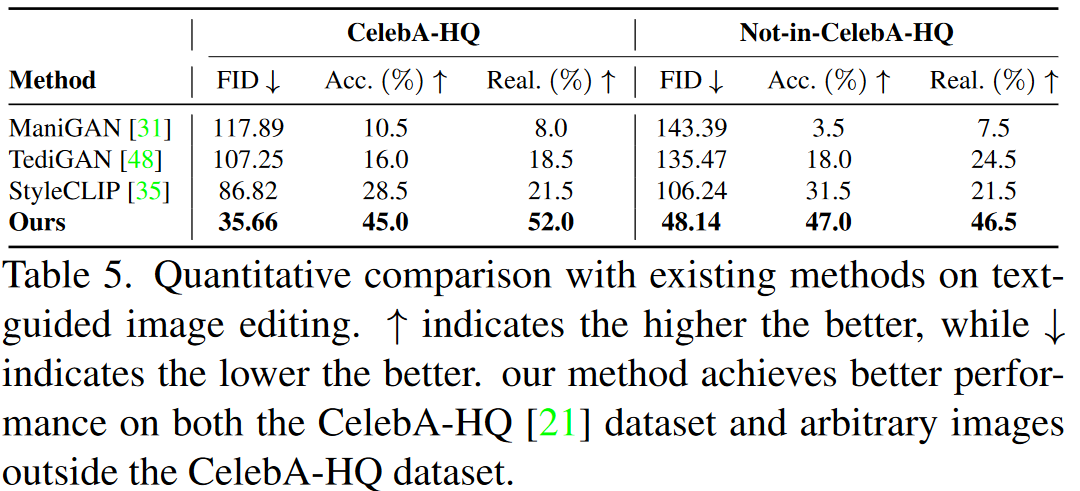
在文本引导图像生成工作中,进行了一系列的实验。论文的方法和现有的方法相比,生成的图像质量比较高,然后也比较符合文本的描述。然后论文进行了用户测试,让20个人对随机抽取生成的10张图片进行评估,证明了论文方法在精确度和真实性两个指标上都比现有的文本引导图像生成方法表现得要好,无论是否在高清人像数据集上相对其他的方法FID指标都有明显降低。然后论文放出图片展现了这个方法生成多样性。
这个是论文方法对文本引导图像编辑的效果。对人脸的保持效果不错。➡️消融实验: 论文对映射网络的层数和选用的预训练CLIP模型进行了消融实验。最终把映射网络层数设为12,对预训练的CLIP模型选用更强的联合空间( ViT / B-16 )。
对损失函数的设计,论文引入了五个损失项,最终的损失是这五个项的加权和。然后特别对对抗损失和多样性损失两项进行了消融实验,最后证明了引入这两个损失模型性能更好。
➡️潜在应用: 对于论文方法的潜在应用,主要就是文本引导图像生成和文本引导图像编辑两个部分,不仅是人脸,也可以用文本引导其他的,比如猫狗建筑这种图像的编辑和生成。
➡️未来展望: 最后是未来展望,这个模型是基于CLIP预训练的模型,CLIP在一些细粒度的和抽象的数据上零样本预测表现一般,没有解决域外泛化的问题,所以在一些数据分布和CLIP预训练数据集的分布差距较大的数据上,这个编辑效果可能也会一定程度的变差,受到了一定程度的限制。